Letzte Aktualisierung am 23. Februar 2026
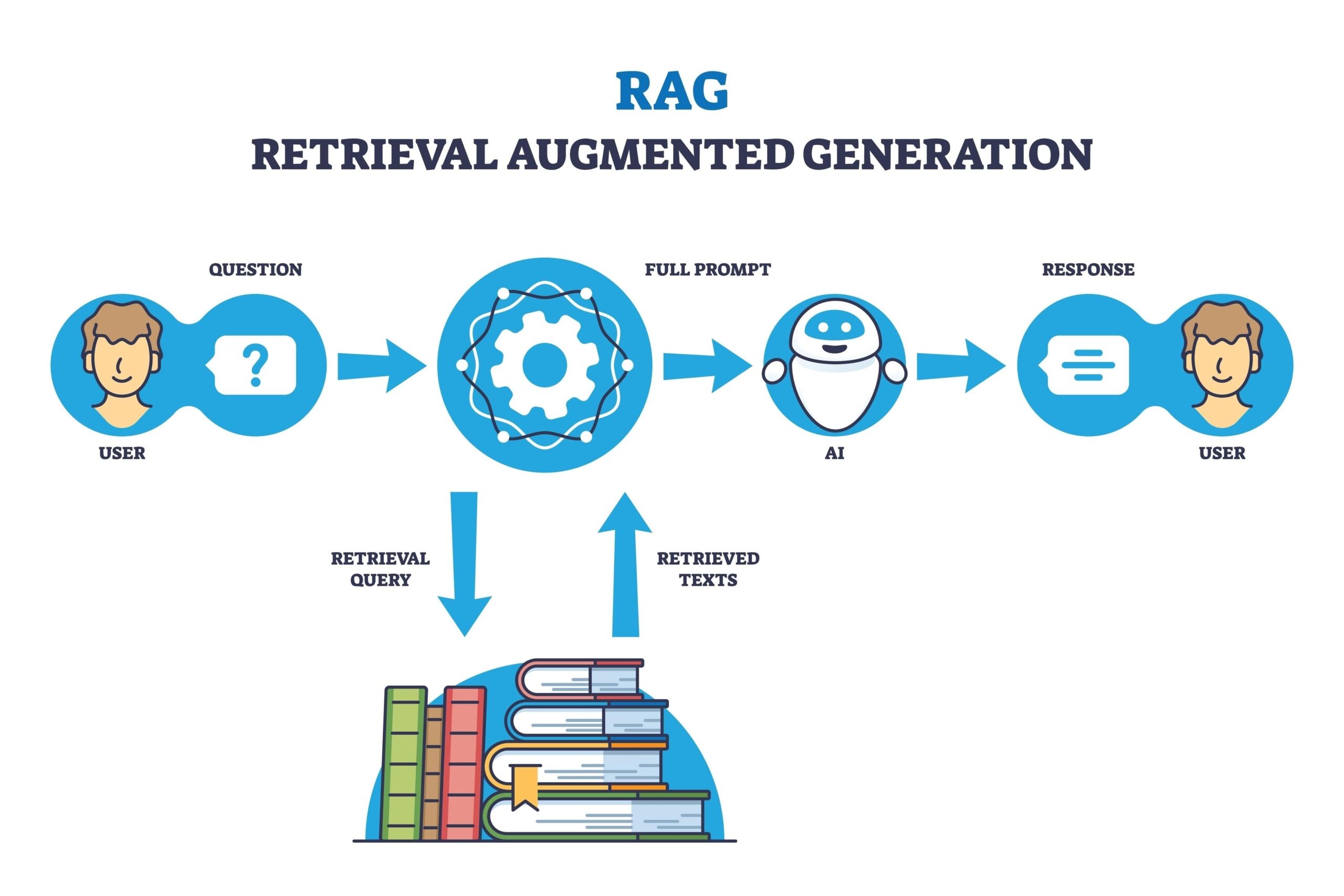
Während Gemini als gewöhnlicher KI-Assistent vermarktet wird und schnelle Ideen und Antworten liefert, ist NotebookLM das Werkzeug für komplexere Analysen und die Erstellung von generativen Inhalten. Die Audiozusammenfassung ist von der Gemini App in NotebookLM gewandert, die sogar wissenschaftlich anmutende Dokumente erstellen kann. Die Kernfunktion von NotebookLM ist die Recherche aus unzähligen Quellen, dazu zählen Notizen (namensgebend), YouTube-Videos, hochgeladene Inhalte und vieles mehr. All das kann mit entsprechenden Prompts in ein Zielformat ausgegeben werden, je nach Länge oder Format ist bis zur Videoerstellung einiges möglich. Das folgende Video hat mir NotebookLM so ausgeliefert, beim Podcast musste ich deutlich mehr Zeit investieren, Selbst einsprechen ginge vermutlich schneller. Wer es nicht sehen kann, die Bilder haben so rein gar nichts mit der eigentlichen Thematik zu tun.
Der merkst.de-Podcast Nummer 211
Beide Ergebnisse wurden aus denselben 39 Quellen erstellt, allesamt Historien von Herstellern, eigenen Artikeln und Podcast-Episoden von der SightCity. Herausgekommen sind in verschiedenen Versuchen Inhalte, die unterschiedlicher nicht hätten sein können. Nur zwei der Ergebnisse haben überhaupt trotz immer gleichem Prompting berücksichtigt, dass ein merkst.de-Podcast 211 entstehen soll und man bitte die Zuhörer alternativ zu mir begrüßen und entsprechend abmoderieren möge. Das Ende der Audiozusammenfassungen endet traditionell immer mit einer Frage, das mag wohl am Training der KI-Daten liegen und so musste ich auch hier nachschärfen. Nachdem ich dann auf die Schnelle mit Lyria 3 in der Gemini-App ein 30sekündiges Intro habe produzieren lassen, benötigte ich dann noch einen Moderationstext. Hier lautete die einzige Quelle folgendermaßen:
Dieser Text ist einfach nur vorzulesen:
„Das war ein mit Lyria 3 und Gemini von Google generiertes Intro. Wir möchten uns vorstellen: Wir sind NotebookLM und führen heute durch diese Show.“
Daraus entstand im Ergebnis zwar ein verwertbarer Prompt, allerdings mit dem unmissverständlichen Tenor, dass man als KI keine Aufgaben einer TTS übernehmen würde und der Zuhörer dafür sicher Verständnis haben wird, aber hört selbst:
Vielleicht waren es zu viele Quellen, ich hätte mehrere Notebooks zu den einzelnen Themenbereichen erstellen und anschließend zusammenführen sollen. Was ich nämlich nicht wusste ist, dass maximal nur 20minütige Audiozusammenfassungen generiert werden und das ist bei einer solchen Komplexität ohne Weglassen natürlich unmöglich. Wer also komplexe Themen beackern will, sollte sich zumindest bei Audio strategisch vorsortieren und nicht alle Quellen in die Zusammenfassung stecken. Das geht nämlich, man kann für jedes Ergebnis die einzelnen Quellen definieren und einen individuellen Fokus setzen. Das bedeutet natürlich immer neue Rechenpower und Energieverbrauch, vor Allem wenn das Ergebnis nicht den Erwartungen entspricht. Es ist quasi wie das Spielen eines Instruments, man lernt mit der Erfahrung und kommt so zu besseren Ergebnissen. Schön ist, dass selbst im Chatfenster aus den Quellen was entsteht, so dass man direkt sieht, welche Daten zu Grunde liegen. Das sind auch die drei Hauptbereiche, Quellen, Chat und Studio.
Die KI-Endlosschleife am Beispiel von Lyria 3 und der Videoerstellung
Zwar befindet sich die Musikkreation noch in der Beta-Phase und wir WISSEN, wie überzeugend spezialisierte KIs Deep Fakes erstellen können, das bleibt generativen Modellen wie Gemini derzeit noch vorbehalten. Ich stelle hier auch stets und ständig fest, dass man – egal ob bei Gemini oder mit ChatGPT – beim Nachschärfen irgendwann an den Punkt kommt, dass die KI nur noch irgendwas produziert. Das hat weniger etwas mit falschen Prompts zu tun, aber mit der mangelnden Anpassungsfähigkeit. Hier habe ich beispielsweise Ein schnelles Video erstellt mit einem Prompt mit der Vorgabe, dass ein Verkäufer ein Bildschirmlesegerät vorführt und der Kunde sich das begeistert anschaut und am Ende meint, er bräuchte aber eigentlich ein Hörgerät. Hier stimmt das Ergebnis ebenfalls nicht mit meiner Vorstellung überein. Problematisch ist dabei natürlich auch die Begrenzung auf nur 30 Sekunden.
Ein Beispiel, das ebenfalls schief ging, ist ein Podcast-Intro, welches ich auf Basis des Originals von MosaicSound erstellen wollte. Dazu habe ich das Original hochgeladen mit der Bitte, es mit Text zu versehen. Heraus kam ein überhaupt nicht an das Original erinnerndes Ergebnis, das überdies nichts mit meinen Vorgaben zu tun hat. Selbst mein Wunsch, keine Hitakkorde oder Schlager zu berücksichtigen und auch kein Hip-Hop zu erzeugen, wurde nicht realisiert. Selbst wenn Gemini behauptet hat, es sei jetzt anders, klangen die Ergebnisse noch mehr nach Schlager. Hier ein Beispiel, das zumindest ansatzweise in die grobe Nähe kommt, die nachfolgenden waren dann wieder sehr schlagerlastig.
Im Gegensatz dazu sind kurze und präzise Angaben kein Problem und führen fast immer zu richtig guten Ergebnissen. Meinem Freund André Kaiser wollte ich mitteilen, dass ich sein Notebook fertig habe, das er als Musiklieferant im Clubhaus seines Motorradclubs Old Germans MC Backland e.V. einsetzt und das sollte natürlich Metal sein. Dies klappte bereits mit der ersten Anweisung erstaunlich gut. Das hat übrigens mit den meisten Musikstücken so gut funktioniert. Das gilt übrigens auch für Artefakte, die ebenfalls kaum ins Gewicht fallen.
Dann ist da noch Werbung. Warum nicht 30 Sekunden für einen Werbesond nutzen? Dies habe ich auf Basis der einstigen LISA der mobilen Hilfsmittelzentrale Deininger GmbH versucht und ganz ehrlich, das könnte man so verwenden.
Oder nehmen wir Mario Krügerke mit seinem MosaicSound, auch hier ein themenbezogenes und sehr überzeugendes Ergebnis.
Ich habe die Tracks als Videoversion mit animiertem Cover eingefügt, alternativ kann man eine MP3-Version mit 192 kBit/s jedoch ohne Cover herunterladen. Um die Tracks als KI-generiert kenntlich zu machen, fügt Google außerdem ein unhörbares Wasserzeichen ein. Bei Anfragen nach stilistischen Künstlern wird darauf hingewiesen, dass Lyria 3 diesbezüglich vorsichtig ist, damit kein Copyright verletzt wird. Dabei scheinen die Ergebnisse einem Zufallsprinzip und keiner ableitbaren Logik zu folgen. Will man beispielsweise nur die Aussprache eines Namens oder Wortes oder Akkordfolgen korrigieren oder einfach nur die Taktart ändern, gibt es in allen Fällen ein anderes Ergebnis als das vorige. Dabei kann Lyria 3 nur 4/4-Takt, ein Waltzer lässt sich somit nicht erstellen, obwohl die KI dies behauptet.
Lyria 3 kann also weder hochgeladene Audios analysieren und verarbeiten, das kennen wir anders von ElevenLabs, noch scheint es sich auf erstellte Ergebnisse beziehen zu können. Nach der Ausgabe bleiben die Prompts erhalten, aber ohne faktische Ergebnisanalyse. Ähnliche Erfahrungen habe ich sowohl bei der Videoerstellung machen müssen als auch mit ChatGPT. Mit DALL·E hatte ich 2024 versucht ein Cover für eine WhatsApp-Gruppe zu erstellen und das Ergebnis wurde mir auch wie gewünscht beschrieben, obwohl es faktisch nur in Ansätzen meinen Vorgaben entsprach. Für blinde Anwender ist es daher wichtig, Ergebnisse mit einer zweiten, hermetisch getrennten KI beschreiben zu lassen. Sicher hat sich diesbezüglich einiges getan, aber in meinen Versuchen gab es höchstens Inspirationen und kaum brauchbare Ergebnisse. Dies hängt möglicherweise auch mit dem so genannten AI Slop zusammen, zu deutsch KI-Müll. Wenn alle ihren Kram fast kostenlos in sämtliche KIs kippen können, lässt sich von den Sprachmodellen schwerer zwischen wahr und falsch differenzieren. Nehmen wir bei Lyria 3 an, dass viele User einen Schlager generieren und Deutsch-Rock im Ergebnis erhalten. Bewerten sie das Ergebnis mehrheitlich als hilfreich, könnte das Modell davon ausgehen, die Aufgabe korrekt erledigt zu haben. Das könnte man auch umgekehrt beschreiben und drückt aus, was ich schon mehrfach beschrieben habe. Am Ende werden Sprachmodelle mit Daten gefüttert und von Menschen geschärft. Das macht sie fehleranfällig, wenn die Datenlage nicht eindeutig ist und es Spielräume durch Unschärfen gibt.
Was können Gemini und NotebookLM?
Datenanalyse und Resynthese könnte dies in zwei Worten beschreiben. Aber ich lasse auch hier mal Gemini arbeiten und dies mit der Anweisung: „Erstelle einen kurzen Artikelteext über die Funktionsweise von Gemini und NotebookLM für meine Homepage.“ Dabei verwende ich den „Thinking-Modus“ für längere und komplexere Aufgaben. Das Ergebnis füge ich hier als Markdown ein. Neu ist übrigens auch bei Copilot, dass die Gedankengänge mit angezeigt werden, man also stets über den Verarbeitungsprozess informiert wird.
KI im Fokus: Wie Gemini und NotebookLM eure Arbeit verändern
Die technologische Entwicklung im Bereich der Künstlichen Intelligenz hat mit Modellen wie Gemini und spezialisierten Anwendungen wie NotebookLM neue Maßstäbe gesetzt. Doch wie unterscheiden sie sich eigentlich in ihrer Arbeitsweise?
Gemini: Das universelle Multitalent
Gemini ist Googles modernstes Sprachmodell. Es ist multimodal konzipiert, was bedeutet, dass es nicht nur Text verarbeitet, sondern auch Bilder, Audio-Dateien und Videos versteht und generieren kann.
Funktionsweise: Gemini basiert auf einem riesigen neuronalen Netz. Es berechnet Wahrscheinlichkeiten für Wortfolgen und erkennt komplexe Zusammenhänge. So kann es Fragen beantworten, Programmcode schreiben oder kreative Texte verfassen.
Euer Vorteil: Es agiert als Generalist und greift auf ein breites Weltwissen zurück, um euch als digitaler Assistent im Alltag zu unterstützen.
NotebookLM: Euer privater Experte
NotebookLM nutzt zwar die Intelligenz von Gemini, verfolgt aber einen völlig anderen Ansatz: das sogenannte Source-Grounding.
Funktionsweise: Hier bestimmt ihr die Datenbasis. Ihr ladet eigene Dokumente, PDFs oder Webseiten-Links hoch. Die KI nutzt dann ausschließlich diese Quellen, um Fragen zu beantworten oder Zusammenfassungen zu erstellen.
Euer Vorteil: Da die Antworten direkt auf euren Dokumenten basieren, werden falsche Fakten minimiert. NotebookLM fügt zudem stets Quellenbelege an, damit ihr genau prüfen könnt, aus welchem Absatz die Information stammt. Es ist damit das ideale Werkzeug für die Recherche oder die Analyse komplexer Themengebiete.
Fazit
Zusammenfassend begeistern mich die Ergebnisse schon, zumal ich NotebookLM tatsächlich häufig für komplexe Themen nutze. Allerdings dauern selbst lange Audiozusammenfassungen maximal nur 20 Minuten, selbst wenn man andere Anweisungen gibt. Für einen schnellen Querschnitt, Vergleichen von Quellen oder Anfangsrecherchen auf Basis einer faktischen Datenlage ist NotebookLM wirklich gut. Einzig im Web wirkt das Ganze optisch zwar ansprechend, für Screenreader allerdings etwas überladen. Im Vergleich mit ChatGPT für rund 22 Euro pro Monat kostet mich Gemini Advance, Pro oder wie Google es aktuell nennt inklusive AI-Funktionen für Fotos, 5 TB Cloud-Speicher und Möglichkeit zum Teilen mit sechs Familienmitgliedern rund 250 Euro pro Jahr, da kann man eigentlich nicht meckern.
Hätte in der Technik-Mailingliste nachgefragt wie es zum Podcast 211 gekommen ist und wie er realisiert wurde. Da bist Du Stephan, mir zuvor gekommen. Viele Grüße von Thomas
Ja Thomas, das hat offenbar nicht nur Dich irritiert und war zugegebenermaßen von mir auch nicht ganz unbeabsichtigt. Ich werde den Artikel hier wohl noch um Alternativbeispiele ergänzen, weil mir das so etwas unkonkret scheint. Man soll ja auch verstehen, wie NotebookLM mit Inhalten umgeht und was am Ende dabei als produktives Ergebnis entstehen kann.
Hallo Stephan,
auch wenn ich Deinen Podcast schon länger verfolge, bringt es die Episode 211 einfach auf den Punkt: Um einfach den Stand der Technik im Hilfsmittelbereich eindrucksvoll zu dokumentieren, liegt es doch nahe, dies von einer KI präsentieren zu lassen. Trotz einiger AusSprachefehler, inklusiv deines Wohnortes, ist doch aus technischer Sicht verdammt viel richtig dargestellt.
Und da ich selbst nur ein Jahr älter bin wie du, habe ich die Entwicklung doch ähnlich bis heute mit verfolgt.
Hier läuft immer noch eine Handy Tech Modular 84 aus dem Jahr 2000, Im Keller steht seit einem Jahr eine Miele Guideline, und das iPHone 16E begleitet mich täglich. Auch das der Buchwurm, die Braille Wave bis hin zur Active Braille Erwähnung finden unterstreicht, daß es Handy Tech bzw. Help Tech bis heute konstant am Markt vertreten, immer geschafft hat, durch neue Innovationen Produkte zu etablieren, welche durch neue Merkmale Akzente am Markt gesetzt haben.
Ich sage an dieser Stelle einfach einmal „Danke“ für diesen historischen Streifzug vom Optacon bis zur OrCam und verbleibe mit herzlichen Grüßen aus der Republik
Markus Klay
Hallo mein Lieber, das ist ja schön mal was von Dir zu lesen. 😉 Aber ich muss das dennoch etwas relativieren: Das Ding ist ja nur so gut geworden, weil ich sämtliche Fragmente in einen neuen Bezug gesetzt habe. Das Zusammenschnippeln hat mehr Arbeit gebraucht als die Erstellung. Die einzelnen Sprachdateien von rund 16 bis 20 Minuten hätte ich so nicht veröffentlichen können. TextBeispielsweise wurde behauptet, Frans Tieman habe 1975 Optelec gegründet, sachlich falsch. Ebenso die Aussage, was ist von den Playern heute noch übrig? So gut wie keiner, sind alle vom Markt verschwunden, weil die Hersteller ihre Screenreader heute fest integrieren. Im Ergebnis war es echt nicht einfach, aus diesen ganzen Fragmenten, teilweise geschnitten in einzelnen Dialogteilen aus unterschiedlichen Vorlagen, am Ende etwas Brauchbares zu erhalten. Trotz dass die Artikelvorlagen alle gut recherchiert waren, hat NotebookLM den gesamten Kontext teils auseinandergepflückt. Daher verwundert es auch nicht, warum sich der eine mit den Sehbehinderten befasst hat und die andere mit den Blinden, denn das klappte selbst in der Einzeldatei schon nicht. Interessant ist, wenn man mal auf den individuellen Wissensstand der Protagonisten achtet. Das konnte ich durch die Nachbearbeitung kaschieren, aber es kommt vor, dass einer was zu einem Thema sagt und später plötzlich so nachfragt, als habe er davon überhaupt keine Ahnung mehr. Das Ganze ist also so skurril und faktisch wäre das auf diese Weise im Original nie sendefähig.
Ein Problem, das ich schon lange bei allen getesteten Modellen und Aufgabestellungen mit unterschiedlicher Datenlage beobachte. Im Grunde klappt das alles ganz gut, wenn man nicht zuviel nachschärft. Da kommt die KI schnell an einem Punkt, dass sie sich quasi wie aufhängt und gar keine oder die vollkommen falschen Ergebnisse produziert, im schlimmsten Fall wie im ersten Schritt ohne sämtliche Korrekturen oder mit Halozinationen. Dabei ist es völlig egal, ob man mit Texten, Videos oder Musik arbeitet, das kann man mit ChatGPT und Gemini im Videomodus auch erleben, wenn man versucht, ein sich stetig änderndes Display zu überwachen um Einstellungen vorzunehmen. Selten klappt das mal gut, meistens klappt es brauchbar und oft hängt Gemini dann fest und egal was Du vor die Linse packst, wird die Antwort dutzendmal wiederholt. Die Ursachen dafür sind mir nicht klar, entweder zu viele Daten oder Widersprüche, vielleicht aber auch eine künstliche Reduktion zur Ressourceneinsparung, ich weiß es nicht. Es kann aber gut sein, dass wenn man die aufgerufenen Gebühren von rund 200 Euro pro Monat aufbringt, die Ergebnisse drastisch besser werden, aber das Geld ist mir es die Sache nicht wert, da schreibe ich lieber selber.